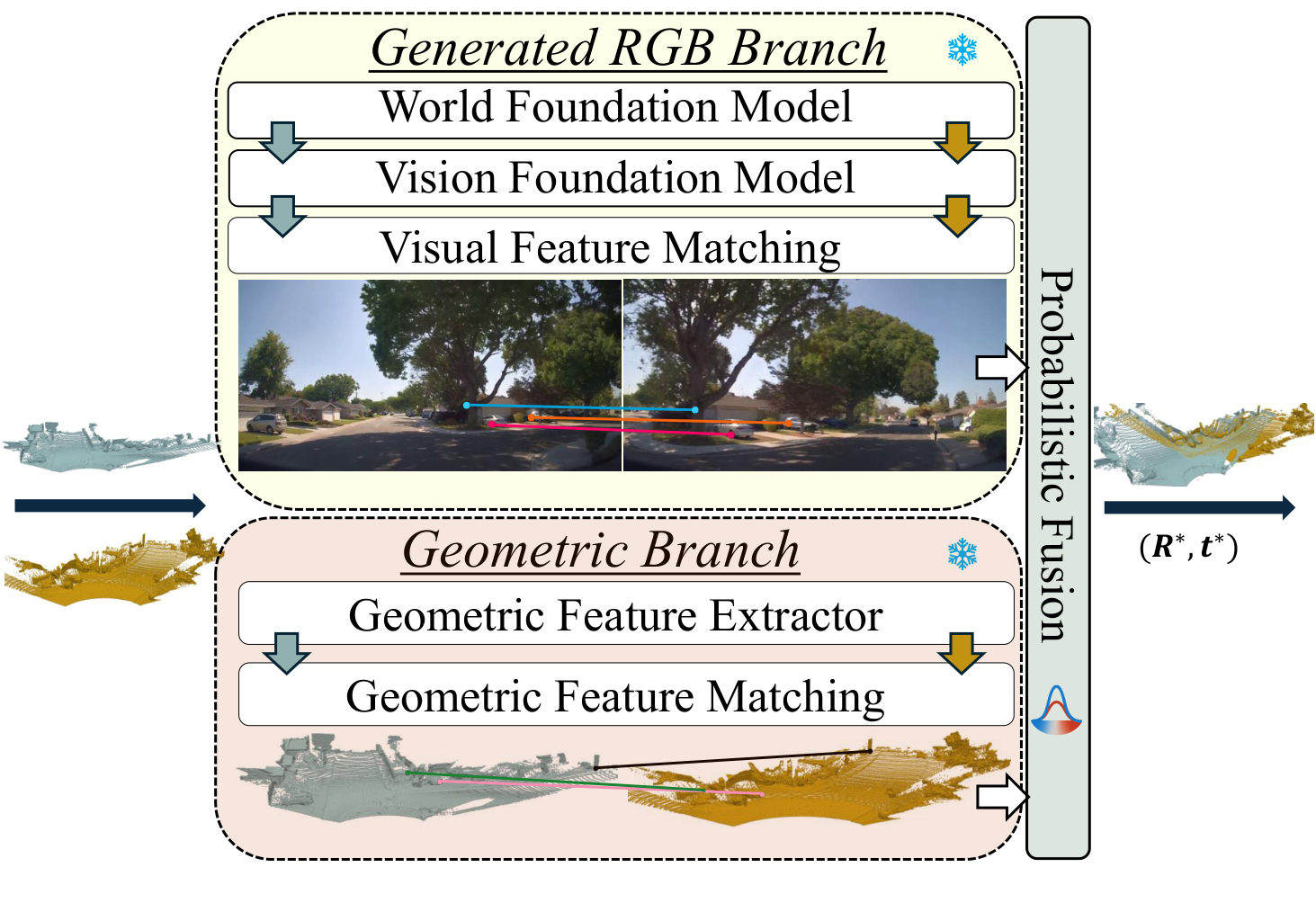
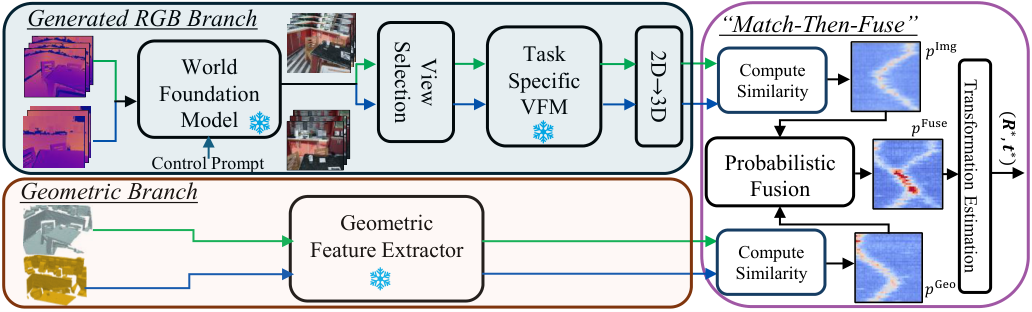
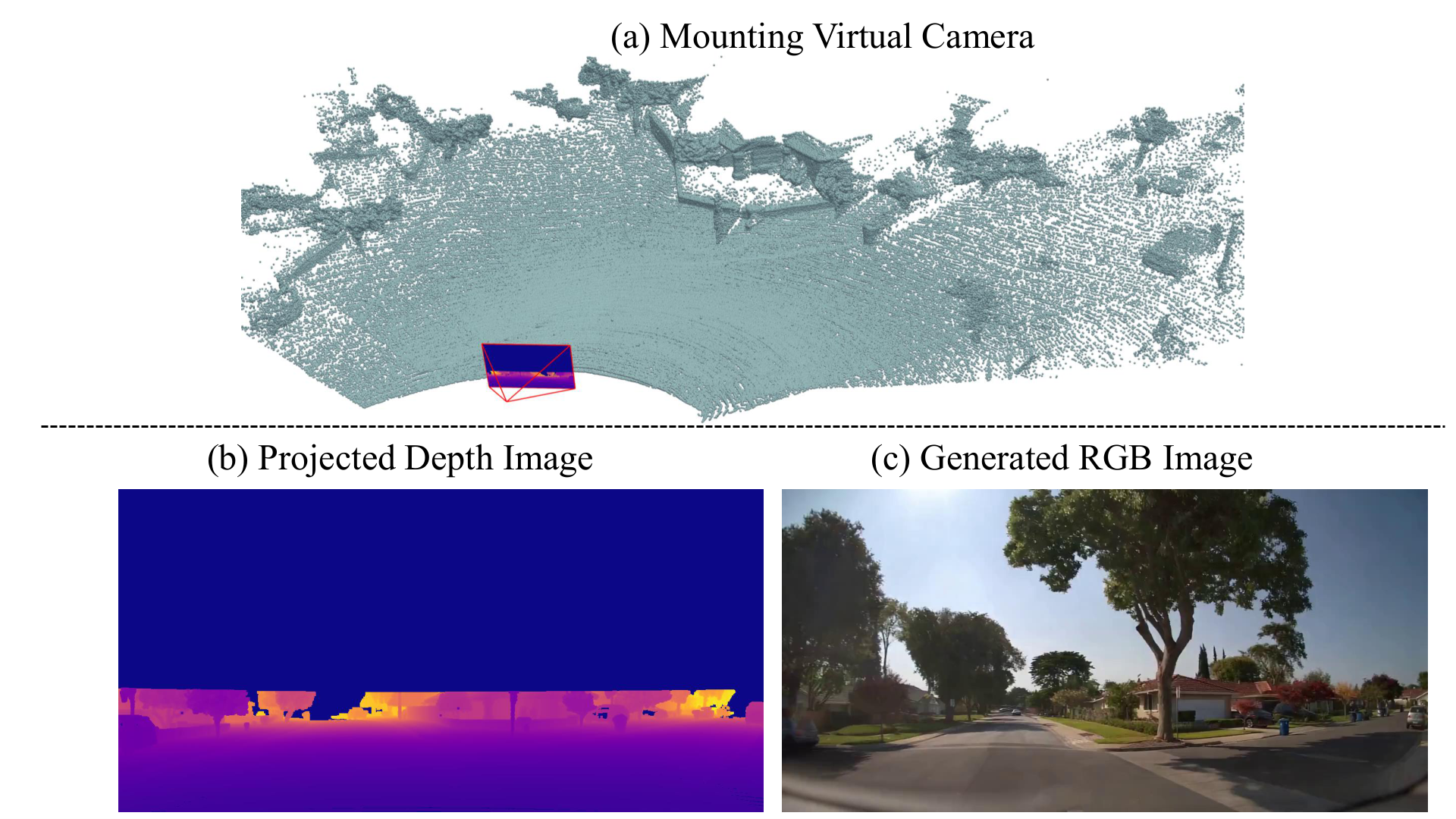
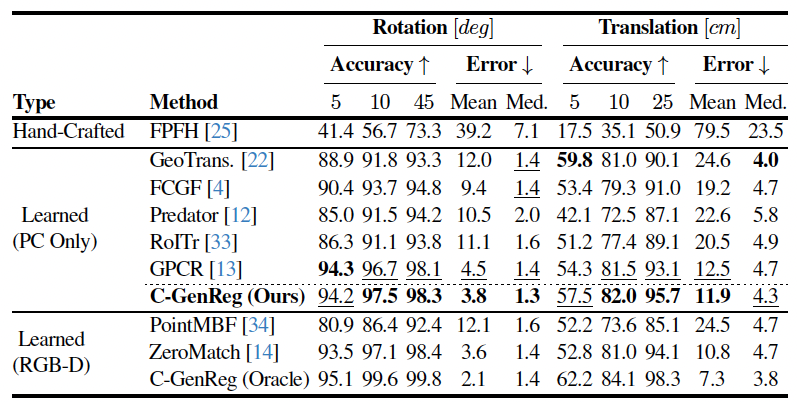
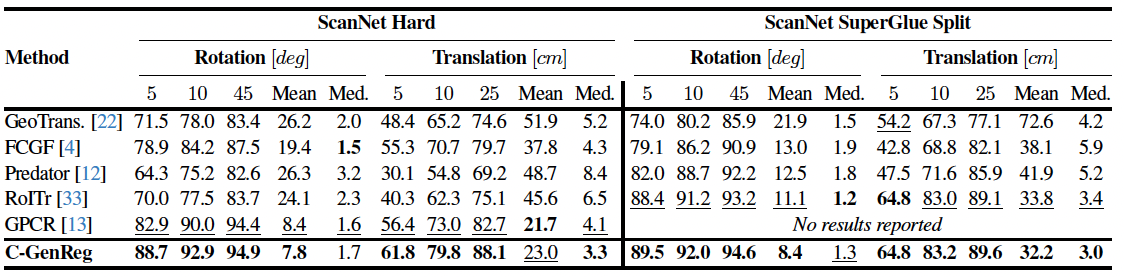
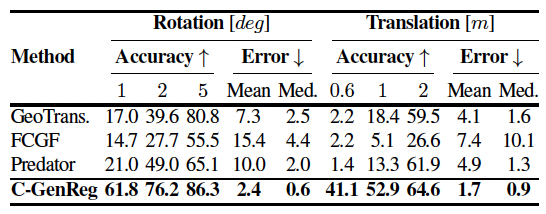
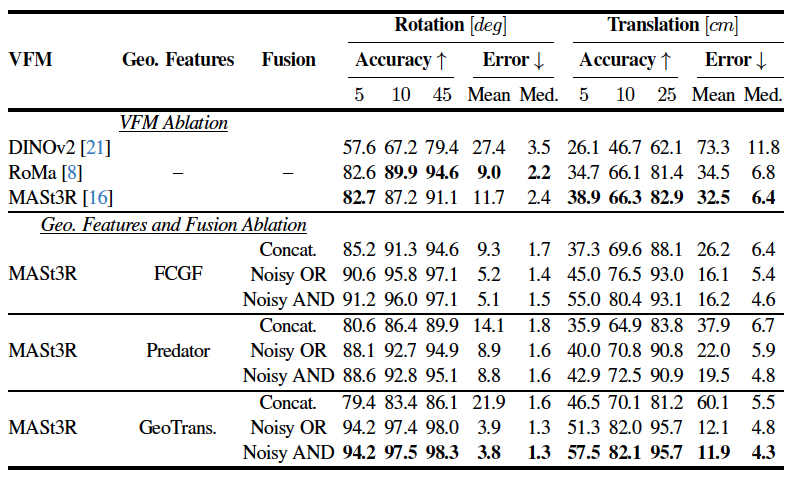
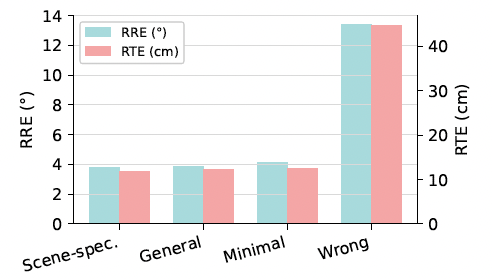
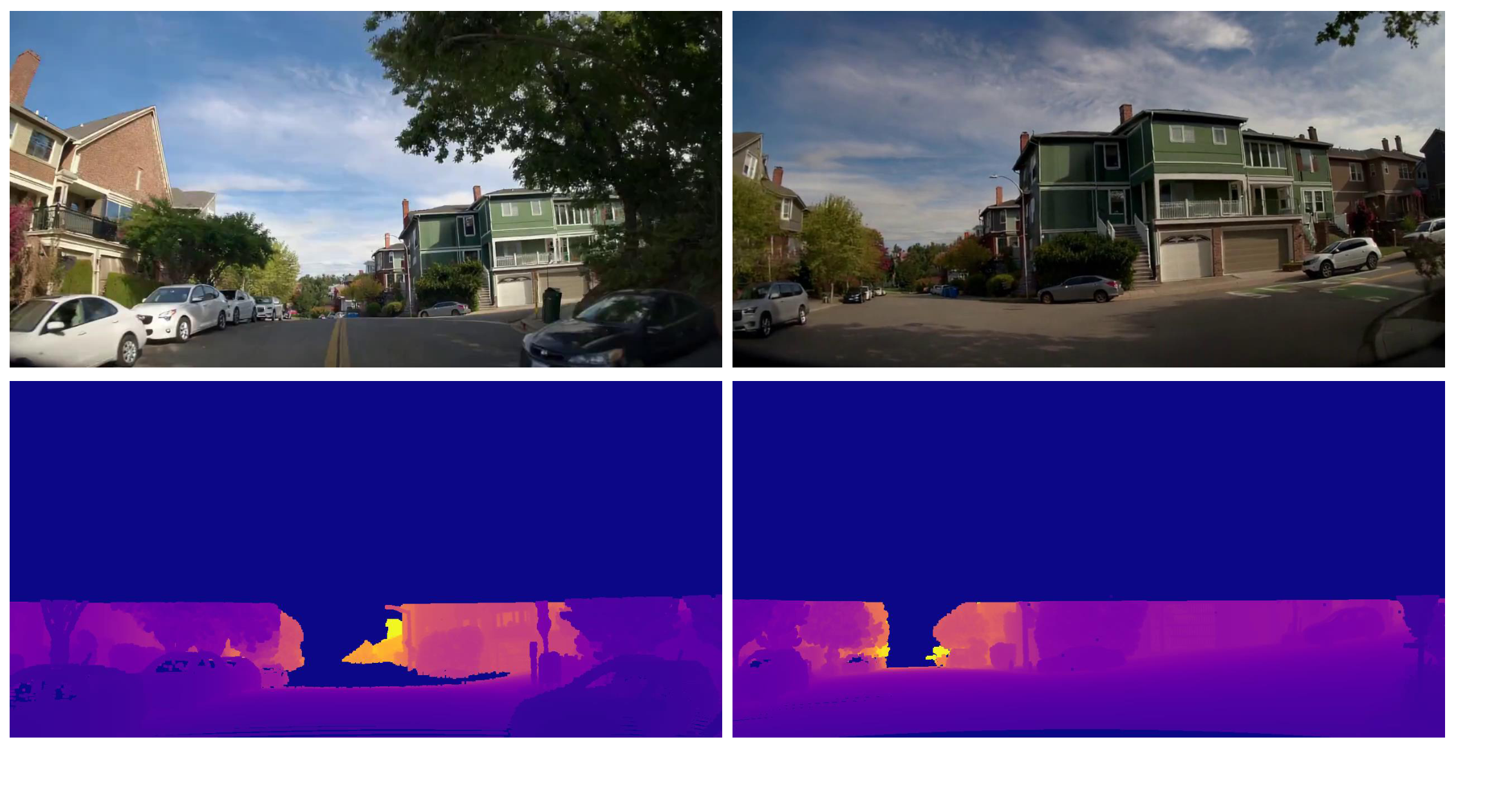
We introduce C-GenReg, a training-free framework for 3D point cloud registration that leverages the complementary strengths of world-scale generative priors and registration-oriented Vision Foundation Models (VFMs). Current learning-based 3D point cloud registration methods struggle to generalize across sensing modalities, sampling differences, and environments. C-GenReg augments the geometric registration branch by transferring the matching problem into an auxiliary image domain, where VFMs excel, using a World Foundation Model to synthesize multi-view-consistent RGB representations from the input geometry.
This generative transfer preserves spatial coherence across source and target views without any fine-tuning. From these generated views, a VFM pretrained for dense correspondences extracts matches, which are lifted back to 3D via the original depth maps. To further enhance robustness, we introduce a Match-then-Fuse probabilistic cold-fusion scheme that combines the generated-RGB and geometric correspondence posteriors. This principled fusion preserves each modality's inductive bias and provides calibrated confidence without any additional learning. C-GenReg is zero-shot and plug-and-play, and experiments on 3DMatch, ScanNet, and Waymo demonstrate strong zero-shot performance, superior cross-domain generalization, and successful operation on real outdoor LiDAR data where imagery is unavailable.